How we decided the bot-like behaviour
Many tweets appeared several times in the dataset. Some of them by natural causes, since users had retweeted the same tweets and users were retweeted internally by other bots as well. However, an enormous amount of “original” content appeared multiple times.
We investigated these duplicated “originals”, and took a closer look at how many times they appeared in the dataset.
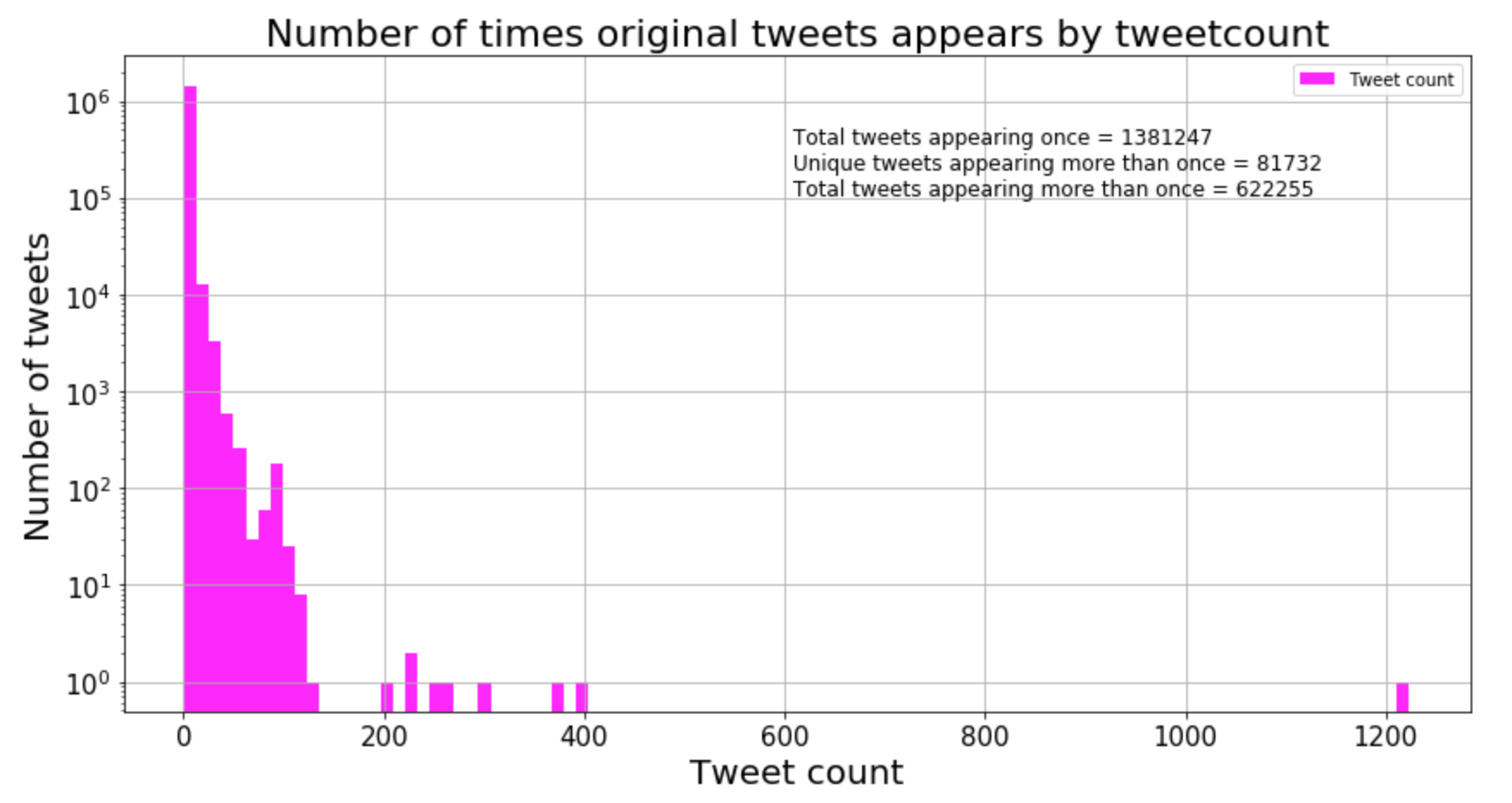
Many of the original tweets are not really that original in the words literal sense. If you look at how many unique tweets that are tweeted more than once, the amount does not seem too surprising. However, when you look at the number of times these unique tweets have been tweeted, this clearly indicates systematically use of bots. The following table shows the stats of original content in a more tidy form.

The tweets marked as original content does not include retweets, and we also removed links from them. These five tweets appeared the most.
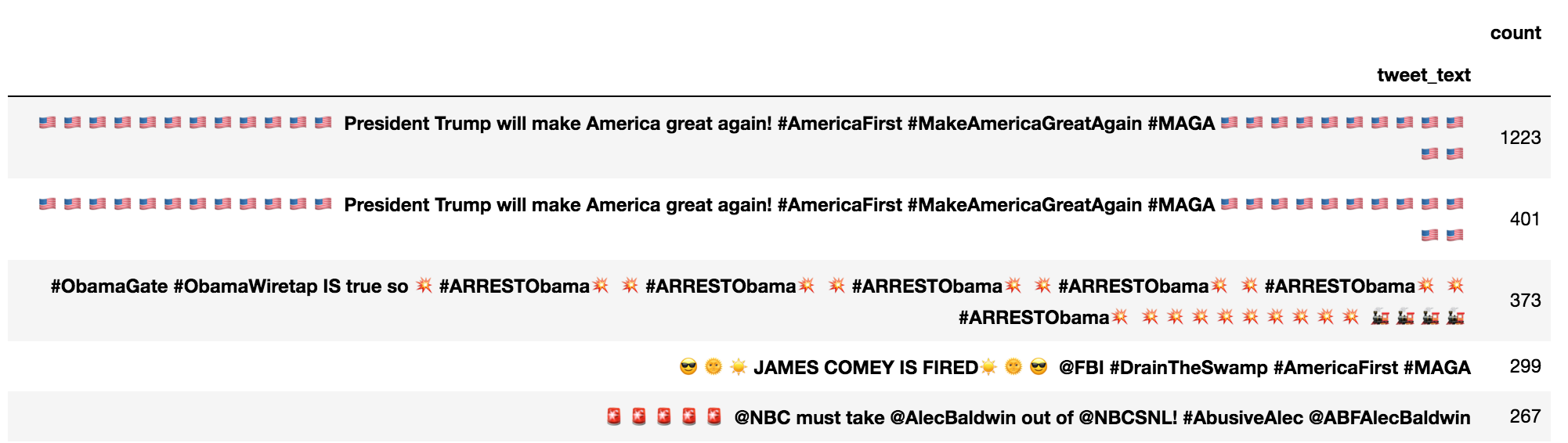 The significant length of these makes it unlikely for users randomly tweeting this sequence of words. We analyzed all the text that appears 75 times or more, and concluded that only three entries needed removal: “I added a video to a @YouTube playlist”, “Comment here on” and “awesome”, since they are valid things to attach in front of links and the last one is just a single word.
The significant length of these makes it unlikely for users randomly tweeting this sequence of words. We analyzed all the text that appears 75 times or more, and concluded that only three entries needed removal: “I added a video to a @YouTube playlist”, “Comment here on” and “awesome”, since they are valid things to attach in front of links and the last one is just a single word.
We found out that 926 of 2286 users had this type of behaviour, which is 40,5% of the dataset. Some of them may have slipped in by randomingly tweeting the same as 75 other tweets, but this likely concludes that a Botnet is used.
The percentage here is taken from all users that tweet in english. In future visualizations regarding the question whether someone can detect Twitter trolls we will also limit the tweets to being “impacting tweets”. This means we will remove the users with under 10 tweets, which will elevate the percentage of bots.
Placing users and likely bots into ranges of followers and total tweets
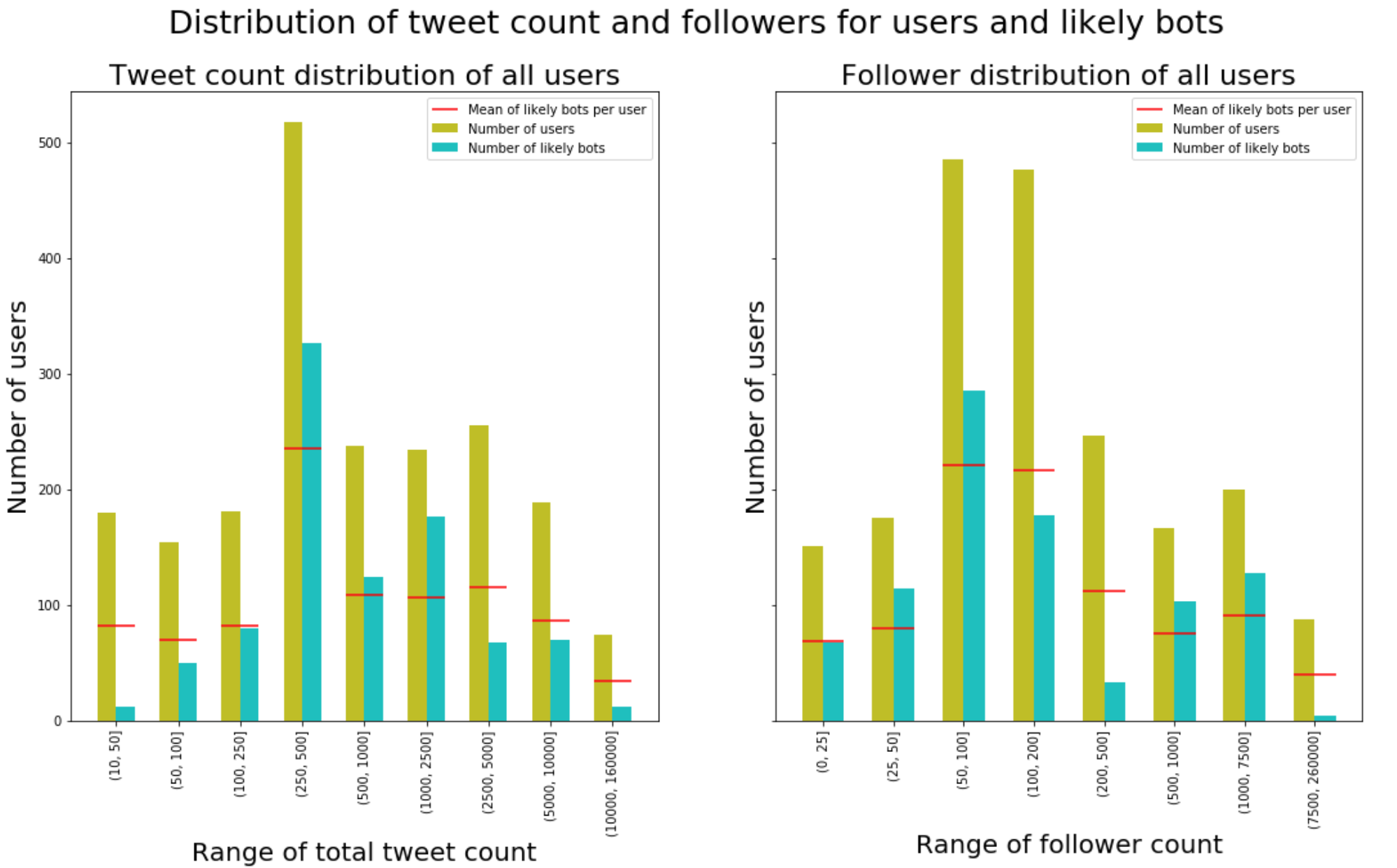
Trolls with under 10 tweets are not included, removing 8 likely bots. The mean of likely bots per user legend (red line) means the expected number bots of total users in each bucket.
If the trolls are bots it is more likely that they have reached a number of tweets. There may be sub-ranges that have higher amount of bots than others as well, since our ranges are randomly picked to have a more distributed visualization. The amount of followers is more evenly distributed. The reason why the bucket of (200, 500] followers has that low amount of likely bots is most likely a coincidence.
We could also have limited ourselves to over 50 tweets, since the number of bots is far from matching the expected value.
The most interesting parts are on the right side of both subplots. Even though having the largest amount of tweets and followers, they don’t tweet the same duplicated content in spite of having a much higher sample size.
One can detect these users as bots on Twitter in general by searching for the same content in the search menu in Twitter. If the content appears numerous times, there is a high propability for it being a bot. More on this in Can normal Twitter users detect Russian trolls?.
Was this interesting? Check out our other analysis: